Huawei Technologies used its annual Connect conference this week effectively declared the end of America’s unipolar reign over high-performance AI computing. Breaking years of enforced silence.. the company laid out an multi-year chip roadmap and showcased a new “SuperPoD” architecture so vast in scale that it reframes the entire debate on technological supremacy.
The strategy articulated by rotating chairman Eric Xu “Because of U.S. sanctions, we cannot manufacture our chips at TSMC.. so our single-chip performance still lags behind NVIDIA,” Xu admitted. “But Huawei has more than thirty years of experience in connecting people and machines… we’ve made breakthroughs that allow us to build super-nodes with tens of thousands of cards. This gives us the ability to deliver the most powerful compute in the world at the system level.”
This is a strategy pulled directly from the pages of science fiction in Liu Cixin’s The Three-Body Problem. Faced with an enemy whose fundamental physics were superior they couldn’t build a single more powerful weapon. Instead they were forced to organize their entire society into a massive human computer using millions of individuals as simple logic gates on or off, flag up or flag down to perform calculations on a scale their foe couldn’t comprehend.

They are winning by building a bigger and faster brain.
As company founder Ren Zhengfei has noted.. it is their deep expertise in mathematics and communication that forms the foundation of their power. “Using mathematics to supplement physics.” This is their core strategy philosophy of using superior architecture and algorithms to overcome hardware limitations. While the US denied them access to the lithography that defines Moore’s Law, Huawei chose to play a game of “Non-Moore’s Law to supplement Moore’s Law.”
On a single chip basis, the incoming Ascend 950 reaches parity with Hopper. 960 will be on par with Blackwell. 970 targeting Rubin+ perf.
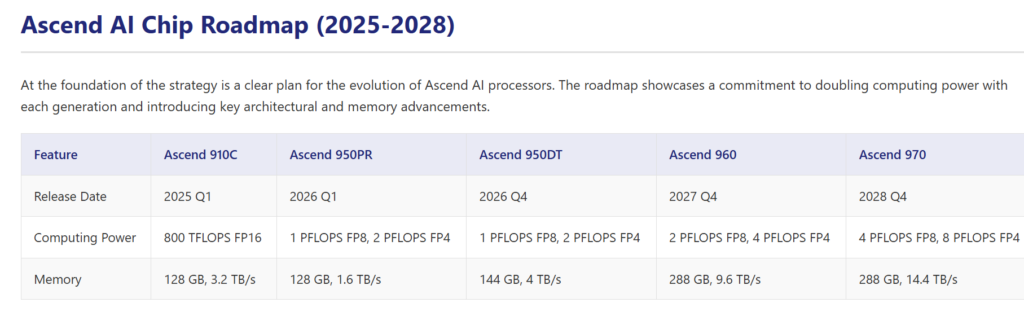
It doesn’t stop here. Obviously you can connect these superpods to form a large cluster. 950 supercluster will have 520k chips connected together while 960 supercluster has over 1m. The end FP8 compute will reach 524 exaflopers and 2.2 zetaflops respectively.
It’s beautiful to watch the so-called “neutral” analysts at places like SemiAnalysis. Just last week their narrative spread across Western tech media was that China’s AI dreams would die by being starved of the advanced High-Bandwidth Memory (HBM) they couldn’t possibly make themselves.
Then next day Huawei’s Eric Xu in Shanghai and casually mentions they now have their own proprietary HBM.
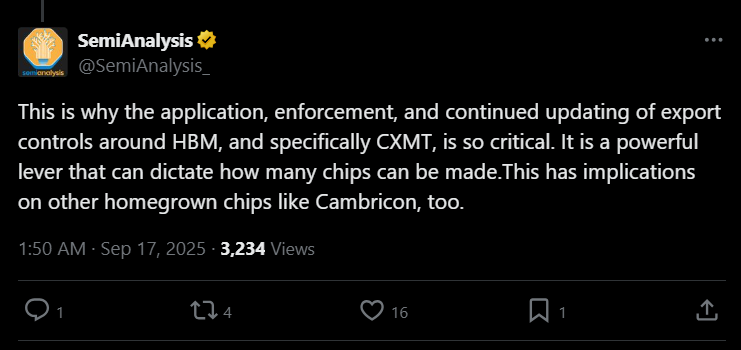
This was never about objective analysis. They are desperately searching for the next choke point and the next tool to maintain control while the rest of the world is expected to stay in its place.
By using custom HBM standard whilst NVIDIA only customize the base die of HBM4, Huawei is ahead. But its sources of DRAM (Swaysure) is slightly behind in DRAM die.
In terms of networking.. Huawei is massively ahead of NVIDIA thanks to Huawei’s years of networking know-how and advanced vertical integration across all layers of optical networking. Most importantly, new Ascend chips now support SIMT to improve CUDA compatibility. All things considered, Huawei is now possibly the biggest contender to NVIDIA in merchant AI chips.
This technological flex was synchronized with a political shot. As Huawei showcased its roadmap, reports confirmed Beijing had ordered its tech companies to halt all purchases of NVIDIA’s chips.
Washington forced a company that was once a customer to become a vertically integrated full-stack rival with its own chips, its own HBM, and a revolutionary system level architecture all while being entirely employee-owned – a concept that makes Wall Street’s head spin.
As Xu laid out the future of Chinese AI, the real message was left unsaid: Washington started this fight, and Huawei is now poised to finish it.



